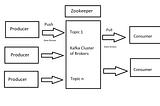
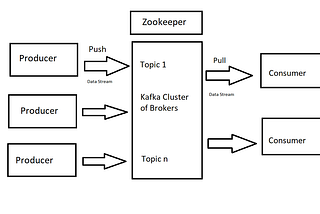
PinnedRajaram SuryanarayananinCodeXStreaming Live Network Packets Data in to Spark Streaming Using KafkaA step-by-step beginners’ guide in Python, to try Kafka with Spark Structured streaming using Network traffic data as an use case.14 min read·Sep 13, 2021--1--1
PinnedRajaram SuryanarayananinGeek CultureTime Series Forecast Using Deep LearningAn Exercise In Keras Recurrent Neural Networks And LSTM14 min read·Jul 22, 2021--2--2
Rajaram SuryanarayananinGeek CultureClassical Time Series Forecast in PythonAn example using classical time series analysis methods (SARIMA)11 min read·Jul 17, 2021----
Rajaram SuryanarayananinGeek CultureAnomaly Detection On IP Address DataAn Example using Gaussian Mixture Modeling (GMM) Clustering12 min read·Jun 23, 2021----
Rajaram SuryanarayananinGeek CultureDeployment Of A Locally Trained Model In Cloud Using AWS SageMakerA Detailed Step-by-Step Guide With Example.13 min read·May 26, 2021--10--10